I didn’t really set out to learn Docker when I started the MDS-in-a-box project, but as it turns out, Docker is quite a good fit. Part of this is because I desired to run the project in a Github Action, which is a very similar paradigm, and also because I have the notion (TBD) of running a bunch of simulations in AWS Batch. The goal of this post is to show a quick demo and then summarize what I learned – which frankly will also serve as a quick reference for me when I use Docker again.
Running the project in Docker
Once Docker Desktop is installed, building the project is trivial with two ‘make’ scripts.
make docker-build
make docker-run-superset
This takes a few minutes, but once its complete you have a full operational analytics stack running inside your machine.
The first rule of Docker
I learned this one the hard way, as I attempted to add evidence.dev to my existing container. The environment was only based on Python, and I needed to add Node support to it. I tried and tried to modify the dockerfile to get Node working – which leads to the first rule of Docker:
Thou Shalt Use An Existing Base Image
As it turns out, a quick googling revealed that there was already an awesome set of python+node base images. Shout out to this repo which is what I ended up using: Python with Node.js.
Now that I had the Docker container “working” – I needed to actually figure out which docker commands to use.
Docker Quick Reference
These are the commands that I learned and used over and over again as I triaged my way through adding another component to my environment. It is not exhaustive but designed to be a practical list of key commands to help you get started with Docker, too.
docker build – use this to build the image defined in your working directory. In my project, I’m also giving it a name (-t mdsbox) and defining where to save it, so the full command is ‘docker build -t mdsbox .‘
docker run – use this to run your image as a container once its built. You also pass in your environmental variables as part of docker run, so this command gets a bit long. Unfortunately, this is the first command that you see when learning Docker, which makes it look more imposing and scary than it actually is. The general syntax is ‘docker run <docker config> <CLI command>‘.
docker ps – use this command to see which containers are running. This is so you know which containers to stop or to access (via docker exec) within the CLI.
docker stop – this command stops a container. If you run a container from the terminal, you can’t stop it or exit like a process running in the terminal (i.e. with Ctrl+D), so you need to use ‘docker stop <container name>‘ instead!
docker exec – this command lets you run a command on a running container. I found this be absolutely huge for debugging as you can get right into the terminal on your container and futz around with it. The command I used to access it is ‘docker exec -it <container name> /bin/bash‘ which drops you into the terminal.
–publish – I’m including this Docker flag, since this is the flag you invoke to make your application visible on the network. Used in context, it looks something like this: ‘docker run –publish 3000:3000 <container name>‘. It is simply mapping port 3000 on the host to port 3000 on the container.
There are some notable exclusions, like ‘docker pull‘ but this reference is merely to help get started with MDS-in-a-box. By the way, you can check out the latest deployed version at www.mdsinabox.com!
As a note, I want to thank Pedram Navid & Greg Wilson for being my Docker shepherds – I definitely was stuck a few times and your guidance was incredibly helpful in getting things unstuck!
I once was tasked with figuring out how to ‘democratize data’ for internal employees. No other instructions, solely a general pain point of ‘the data team is stuck doing ad-hoc tickets’ and ‘stakeholders want to get data on their own.’ After floundering for a while, I set out to figure out what data self-serve looked like at other companies. Seemed simple enough. But I quickly learned things aren’t that simple, and when are they for cross-functional data projects, anyway?
I want to share what I learned during an earnest effort to stand up data self-serve. I know others are struggling with this same project and its ambiguities and humongous scope. I spent time reading, thinking, attempting, failing, trying again, failing again, trying again and seeing success. Let’s dive in.
Executive Summary
Data rarely moves fast enough across companies to enable data-informed decisions. The data team is a bottleneck behind which many requests stack up in a queue. The data team drowns in questions and stakeholders become frustrated. Long wait times ensue, forcing the business one of three decisions:
(1) Wait to make a decision (2) Make a decision without data (3) Departments hire their own data workers.
The data velocity problem is not reasonably solved through sheer volume of hiring. Data workers are expensive and hard to find. Instead, data teams typically pivot to enabling the business via self-serve and data democratization. Ideally, this unlocks the data team to focus on strategic analyses and initiatives and the business is freed to find the data they need without submitting a ticket.
Effective data teams must pivot away from (or avoid entirely!) taking tickets and into partnership with the organization, focusing on building scalable data solutions from which others can self-serve.
Ability for any employee to quickly find and leverage the data and insights they need for their role without funneling through the Data Team
Good Self-Service Always Looks Different
(and bad self-service always looks the same)
Data self-serve done well, by its very nature, looks very different from company to company. The tools, processes, and organization structure supporting self-serve requires tailoring to the organization, rather than following a blueprint.
This puts data teams in a liberating but uncomfortable position. They’re able to freely define and create the self-service experience that their organization needs at this very moment, but at the same time there’s no blueprint for success. This requires an interactive approach to find the best solution for their company.
The focus must be on the stakeholders’ needs, not the data team’s needs. Data teams have a habit of making data-self serve in their image instead of thinking about who they’re serving. The focus must be and will be squarely on the data self-serve experience of coworkers.
Typical Hurdles to Self-Serve
It’s easy to conjure up a world where someone types or speaks a question into a machine and gets the data they need. This is the ultimate data self-serve utopia and one on full display in the excellent sci-fi show The Expanse. The main characters routinely verbally ask computers questions like “Pull up every ship within X distance which was made by Y company and left Z destination in the last week.”
There are many hurdles before that sort of world is possible. Let’s cover a few of them:
Data operated as a service
Many data teams operate with a “receive a ticket, answer a ticket” mindset. This limits the team’s output into reactive short-term and smaller-scale asks and puts them as a bottleneck between the business and data. This is not an uncommon problem within the data industry. Data service teams are typically overstretched and struggle to answer all the questions coming their way. The business inevitably assumes the data team isn’t a strategic partner as they don’t seem to operate like one. If you operate like a service desk, you’ll be treated like one.
This team structure rarely scales. I recall a discussion with a C-Suite member who criticized the data team as “Getting me answers so late that I’ve forgotten my question by the time they reply.” Ouch.
In contrast, effective BI teams operate with a product-like mindset that focuses on scale and solutions. They partner closely with stakeholders to solve problems and prioritize ruthlessly based on business impact.
Data foundations not yet ready for self-serve
There is an immense amount of work required to get data ready for self-serve. Just cleaning up a few raw data tables isn’t enough. Each part of the business (Sales, Marketing, Product, etc.) need different sets of data to answer their unique use cases.
Prepping data into the right shape requires close partnership and collaboration between the data team and its internal stakeholders. This requires steps like data ingestion and transformation, implementing tooling like Git and dbt and having a team that can support the data lifecycle of a company.
Lack of data literacy
Data literacy, much like self-serve, is a tough term to nail down. This deserves its own discussion entirely, but for now let’s go with a typically squishy definition along the lines of “How well stakeholders can interact with and understand data.”
Training for data literacy is immensely difficult. Even if you have the world’s best data models and data marts and the Modern Data Stack™️ stakeholders will struggle to find value if they can’t grok the internal business data model or fall into common data pitfalls. This hurdle must be overcome no matter how well you do everything else.
Lack of data tools that enable self-serve
Typically there are two primary ways that an individual can self-serve data: SQL on a database or look at a data-team-created dashboard. SQL is great for technical individuals but is not an option for the majority of employees. Dashboards are usually widely available but lack customization. Generally dashboards are a “you get what you get” type of experience, with little to no drill down capability and slow turnaround times from data teams for enhancement requests.
Data teams must provide other options for non-SQL savvy users to explore data in a more ad-hoc sense, leveraging curated/enriched tables created for their department. This can look as simple as providing access to enriched data in Excel or “Reverse ETL” where you send data back to source systems like Salesforce for direct consumption in those contexts.
Data privacy
This varies company to company, but data privacy comes into play depending on industry and company size. And whenever privacy is a factor, data access becomes more difficult. Typical lines in the sand are material non-public information (MNPI) when a company is publicly traded or personally identifiable information (PII) that only specific people should have access to.
Data self-serve almost always runs into data privacy concerns and the height of this hurdle (or wall…) will depend on the company.
But…What Does Good Self-Serve Look Like?!
Even though I described at length that good self-serve usually looks different, there are still some guiding principles to shoot for. These may not be universal and may change depending on your company’s data maturity, but they should be helpful.
(1) Focus initial efforts on specific departments/teams
One common bugaboo is an attempt to boil the ocean. The data team is already spread thin and pivoting everyone to self-serve for all departments at the same time will be too much. Instead, focus on a couple teams or departments with clear self-serve needs. Assign a specific analyst or two for the project who already understands a particular business domain and want to take on the challenge.
This both narrows the scope and increases the likelihood of close partnership with those teams. With partnership will come alignment on business value and understanding of pain points. Everyone wins.
(2) Create roadmap in partnership with stakeholders
Self-serve must necessarily look different from department to department. The needs for Finance are wholly different from Product, Engineering, Field, Legal or Marketing. This is why a focus on self-serve and a dedicated BI partner is so crucial. Requirement gathering and roadmap creation must be done in close collaboration between BI and each department. Examples of requirements to gather include:
Examples of requirements to gather:
* Use cases * Defining personas (technical/non-technical/etc) * Tools needed * Datasets * Training/Enablement
(3) Build source of truth data marts
A data mart is a set of tables designed for ease of use by a department for their self-serve needs. These tables are specifically curated by the data team to make data easy to consume and understand for a particular department.
Just providing individuals with access to the entire database is inevitably overwhelming. There could be hundreds of billions of data points across thousands of columns and hundreds to thousands of tables. Many analysts need a year to become comfortable with data at its most granular state. Expecting non-analysts to just hop in and find value isn’t reasonable.
To avoid this steep learning curve, a curated data mart enables self-service without overwhelming stakeholders. This curated data mart must be built in close collaboration between the data partner and their stakeholders to find the sweet spot of “plenty of data” and “not confusing”.
Example: The sales team needs a few good tables such as Account, Opportunity and Task from which they can build most any report they need.
(4) Create an adoption and discoverability program
Data discoverability is an enormous challenge that must be tackled on several angles. The existence of data marts alone is not enough to drive adoption if individuals do not know how they exist or do not know how to leverage them.
To drive adoption, efforts must include:
* Training / Onboarding sessions for all stakeholders * Clear documentation for all data marts, tools available, key reports * Weekly office hours * Monthly & quarterly prioritization meetings * Deprecation process to clean out old/unused data products
Parting Notes
There’s much more to write and I’ll follow up around defining internal stakeholder personas and choosing technologies that solve different aspects of data self-serve. For now, I hope the key message you took away from this is:
“I’m empowered to figure out how to best do self-serve at my organization.”
There’s an art to this task, and that’s why it’s so difficult to find anyone giving a blueprint. There really isn’t one. And you’ll never “arrive” at the conclusion of this project. You’ll just continually improve it, much like you do all your other data efforts. The fun is in the journey.
TLDR: A fast, free, and open-source Modern Data Stack (MDS) can now be fully deployed on your laptop or to a single machine using the combination of DuckDB, Meltano, dbt, and Apache Superset.
This post is a collaboration with Jacob Matson and cross-posted on DuckDB.org.
Summary
There is a large volume of literature (1, 2, 3) about scaling data pipelines. “Use Kafka! Build a lake house! Don’t build a lake house, use Snowflake! Don’t use Snowflake, use XYZ!” However, with advances in hardware and the rapid maturation of data software, there is a simpler approach. This article will light up the path to highly performant single node analytics with an MDS-in-a-box open source stack: Meltano, DuckDB, dbt, & Apache Superset on Windows using Windows Subsystem for Linux (WSL). There are many options within the MDS, so if you are using another stack to build an MDS-in-a-box, please share it with the community on the DuckDB Twitter, GitHub, or Discord, or the dbt slack! Or just stop by for a friendly debate about our choice of tools!
Motivation
What is the Modern Data Stack, and why use it? The MDS can mean many things (see examples here and a historical perspective here), but fundamentally it is a return to using SQL for data transformations by combining multiple best-in-class software tools to form a stack. A typical stack would include (at least!) a tool to extract data from sources and load it into a data warehouse, dbt to transform and analyze that data in the warehouse, and a business intelligence tool. The MDS leverages the accessibility of SQL in combination with software development best practices like git to enable analysts to scale their impact across their companies.
Why build a bundled Modern Data Stack on a single machine, rather than on multiple machines and on a data warehouse? There are many advantages!
Simplify for higher developer productivity
Reduce costs by removing the data warehouse
Deploy with ease either locally, on-premise, in the cloud, or all 3
Eliminate software expenses with a fully free and open-source stack
Maintain high performance with modern software like DuckDB and increasingly powerful single-node compute instances
Achieve self-sufficiency by completing an end-to-end proof of concept on your laptop
Enable development best practices by integrating with GitHub
Enhance security by (optionally) running entirely locally or on-premise
If you contribute to an open-source community or provide a product within the Modern Data Stack, there is an additional benefit!
Increase adoption of your tool by providing a free and self-contained example stack
Reach out on the DuckDB Twitter, GitHub, or Discord, or the dbt slack to share an example using your tool with the community!
Trade-offs
One key component of the MDS is the unlimited scalability of compute. How does that align with the MDS-in-a-box approach? Today, cloud computing instances can vertically scale significantly more than in the past (for example, 224 cores and 24 TB of RAM on AWS!). Laptops are more powerful than ever. Now that new OLAP tools like DuckDB can take better advantage of that compute, horizontal scaling is no longer necessary for many analyses! Also, this MDS-in-a-box can be duplicated with ease to as many boxes as needed if partitioned by data subject area. So, while infinite compute is sacrificed, significant scale is still easily achievable.
Due to this tradeoff, this approach is more of an “Open Source Analytics Stack in a box” than a traditional MDS. It sacrifices infinite scale for significant simplification and the other benefits above.
Choosing a problem
Given that the NBA season is starting soon, a monte carlo type simulation of the season is both topical and well-suited for analytical SQL. This is a particularly great scenario to test the limits of DuckDB because it only requires simple inputs and easily scales out to massive numbers of records. This entire project is held in a GitHub repo, which you can find here: https://www.github.com/matsonj/nba-monte-carlo.
Building the environment
The detailed steps to build the project can be found in the repo, but the high-level steps will be repeated here. As a note, Windows Subsystem for Linux (WSL) was chosen to support Apache Superset, but the other components of this stack can run directly on any operating system. Thankfully, using Linux on Windows has become very straightforward.
Install Ubuntu 20.04 on WSL.
Upgrade your packages (sudo apt update).
Install python.
Clone the git repo.
Run make build and then make run in the terminal.
Create super admin user for Superset in the terminal, then login and configure the database.
Run test queries in superset to check your work.
Meltano as a wrapper for pipeline plugins
In this example, Meltano pulls together multiple bits and pieces to allow the pipeline to be run with a single statement. The first part is the tap (extractor) which is ‘tap-spreadsheets-anywhere‘. This tap allows us to get flat data files from various sources. It should be noted that DuckDB can consume directly from flat files (locally and over the network), or SQLite and PostgreSQL databases. However, this tap was chosen to provide a clear example of getting static data into your database that can easily be configured in the meltano.yml file. Meltano also becomes more beneficial as the complexity of your data sources increases.
plugins:
extractors:
- name: tap-spreadsheets-anywhere
variant: ets
pip_url: git+https://github.com/ets/tap-spreadsheets-anywhere.git
# data sources are configured inside of this extractor
The next bit is the target (loader), ‘target-duckdb‘. This target can take data from any Meltano tap and load it into DuckDB. Part of the beauty of this approach is that you don’t have to mess with all the extra complexity that comes with a typical database. DuckDB can be dropped in and is ready to go with zero configuration or ongoing maintenance. Furthermore, because the components and the data are co-located, networking is not a consideration and further reduces complexity.
Next is the transformer: ‘dbt-duckdb‘. dbt enables transformations using a combination of SQL and Jinja templating for approachable SQL-based analytics engineering. The dbt adapter for DuckDB now supports parallel execution across threads, which makes the MDS-in-a-box run even faster. Since the bulk of the work is happening inside of dbt, this portion will be described in detail later in the post.
Lastly, Apache Superset is included as a Meltano utility to enable some data querying and visualization. Superset leverages DuckDB’s SQLAlchemy driver, duckdb_engine, so it can query DuckDB directly as well.
With Superset, the engine needs to be configured to open DuckDB in “read-only” mode. Otherwise, only one query can run at a time (simultaneous queries will cause locks). This also prevents refreshing the Superset dashboard while the pipeline is running. In this case, the pipeline runs in under 8 seconds!
Wrangling the data
The NBA schedule was downloaded from basketball-reference.com, and the Draft Kings win totals from Sept 27th were used for win totals. The schedule and win totals make up the entirety of the data required as inputs for this project. Once converted into CSV format, they were uploaded to the GitHub project, and the meltano.yml file was updated to reference the file locations.
Loading sources
Once the data is on the web inside of GitHub, Meltano can pull a copy down into DuckDB. With the command meltano run tap-spreadsheets-anywhere target-duckdb, the data is loaded into DuckDB, and ready for transformation inside of dbt.
Building dbt models
After the sources are loaded, the data is transformed with dbt. First, the source models are created as well as the scenario generator. Then the random numbers for that simulation run are generated – it should be noted that the random numbers are recorded as a table, not a view, in order to allow subsequent re-runs of the downstream models with the graph operators for troubleshooting purposes (i.e. dbt run -s random_num_gen+). Once the underlying data is laid out, the simulation begins, first by simulating the regular season, then the play-in games, and lastly the playoffs. Since each round of games has a dependency on the previous round, parallelization is limited in this model, which is reflected in the dbt DAG, in this case conveniently hosted on GitHub Pages.
There are a few more design choices worth calling out:
Simulation tables and summary tables were split into separate models for ease of use / transparency. So each round of the simulation has a sim model and an end model – this allows visibility into the correct parameters (conference, team, elo rating) to be passed into each subsequent round.
To prevent overly deep queries, ‘reg_season_end’ and ‘playoff_sim_r1’ have been materialized as tables. While it is slightly slower on build, the performance gains when querying summary tables (i.e. ‘season_summary’) are more than worth the slowdown. However, it should be noted that even for only 10k sims, the database takes up about 150MB in disk space. Running at 100k simulations easily expands it to a few GB.
Connecting Superset
Once the dbt models are built, the data visualization can begin. An admin user must be created in superset in order to log in. The instructions for connecting the database can be found in the GitHub project, as well as a note on how to connect it in ‘read only mode’.
There are 2 models designed for analysis, although any number of them can be used. ‘season_summary’ contains various summary statistics for the season, and ‘reg_season_sim’ contains all simulated game results. This second data set produces an interesting histogram chart. In order to build data visualizations in superset, the dataset must be defined first, the chart built, and lastly, the chart assigned to a dashboard.
Below is an example Superset dashboard containing several charts based on this data. Superset is able to clearly summarize the data as well as display the level of variability within the monte carlo simulation. The duckdb_engine queries can be refreshed quickly when new simulations are run.
season summary & expected winsplayoff results
Conclusions
The ecosystem around DuckDB has grown such that it integrates well with the Modern Data Stack. The MDS-in-a-box is a viable approach for smaller data projects, and would work especially well for read-heavy analytics. There were a few other learnings from this experiment. Superset dashboards are easy to construct, but they are not scriptable and must be built in the GUI (the paid hosted version, Preset, does support exporting as YAML). Also, while you can do monte carlo analysis in SQL, it may be easier to do in another language. However, this shows how far you can stretch the capabilities of SQL!
Next steps
There are additional directions to take this project. One next step could be to Dockerize this workflow for even easier deployments. If you want to put together a Docker example, please reach out! Another adjustment to the approach could be to land the final outputs in parquet files, and to read them with in-memory DuckDB connections. Those files could even be landed in an S3-compatible object store (and still read by DuckDB), although that adds complexity compared with the in-a-box approach! Additional MDS components could also be integrated for data quality monitoring, lineage tracking, etc.
Josh Wills is also in the process of making an interesting enhancement to dbt-duckdb! Using the sqlglot library, dbt-duckdb would be able to automatically transpile dbt models written using the SQL dialect of other databases (including Snowflake and BigQuery) to DuckDB. Imagine if you could test out your queries locally before pushing to production… Join the DuckDB channel of the dbt slack to discuss the possibilities!
Please reach out if you use this or another approach to build an MDS-in-a-box! Also, if you are interested in writing a guest post for the DuckDB blog, please reach out on Discord!
If you are using SQL Server with dbt, odds are that you probably have some stored procedures lurking in your database. And of course, the sql job agent is probably running some of those on a cron. I want to show another way to approach these, using dbt run-operations and GitHub actions. This will allow you to have a path towards moving your codebase into a VCS like git.
Unwrapping your wrapper with jinja
The pattern I am most familiar with is using the sql agent to run a “wrapper”, which servers to initialize the set of variables to pass into your stored procedure. The way I have done this with dbt is a bit different, and split into two steps: 1) writing the variables into a dbt model and 2) passing that query into a table that dbt can iterate on.
Since your model to stuff the variables into a table (step 1) is highly contextual, I’m not going to provide an example, but I will show how to pass an arbitrary sql query into a table. Example below:
{% set sql_statement %}
SELECT * FROM {{ ref( 'my_model' ) }}
{% endset %}
{% do log(sql_statement, info=True) %}
{%- set table = run_query(sql_statement) -%}
For those of you from the SQL Server world – the metaphor here is a temporary table. You can find more about run_query here.
Agate & for loops
What we have created with the run_query macro is an Agate table. This means we can perform any of the Agate operations on this data set, which is pretty neat! In our case, we are going to use a python for loop and pass in the rows of our table.
{% for i in table.rows -%}
{% set stored_procs %}
EXECUTE dbo.your_procedure
@parameter_1 = {{ i[0] }}
, @parameter_2 = {{ i[1] }}
{% endset %}
{%- do log("running query below...", info=True) -%}
{% do log(stored_procs, info=True) %}
{% do run_query(stored_procs) %}
{% set stored_procs = true %}
{% endfor %}
The clever thing to do here with python is that we can pass multiple columns into our stored procedure, which differs from something like dbt_utils.get_column_values that can also be used as part of a for loop, but only for a single column. In this case we can reference which column to return from our table with variable[n], so i[0] returns the value in the first column in the current row, i[1] returns the second column and so on.
Building the entire macro
Now that we have the guts of this worked out, we can pull it together in an entire macro. I’m adding ‘dry_run’ flag so we can see what the generate SQL is for debugging purposes, without having to execute our procedure. As a side note, you could also build this as a macro that you run as pre or post hook, but in that case you would need to include an ‘if execute‘ block to make sure you don’t run the proc when project is compiled and so on.
-- Execute with: dbt run-operation my_macro --args '{"dry_run": True}'
-- to run the job, run w/o the args
{% macro my_macro(dry_run='false') %}
{% set sql_statement %}
SELECT * FROM {{ ref( 'my_model' ) }}
{% endset %}
{% do log(sql_statement, info=True) %}
{%- set table = run_query(sql_statement) -%}
{% for i in table.rows -%}
{% set stored_procs %}
EXECUTE dbo.your_procedure
@parameter_1 = {{ i[0] }}
, @parameter_2 = {{ i[1] }}
{% endset %}
{%- do log("running query below...", info=True) -%}
{% do log(stored_procs, info=True) %}
{% if dry_run == 'false' %}
{% do run_query(stored_procs) %}
{% endif %}
{% set stored_procs = true %}
{% endfor %}
{% do log("my_macro completed.", info=True) %}
{% endmacro %}
Running in a Github action
Now that we have the macro, we can execute in dbt with ‘dbt run-operation my_macro’. Of course, this is great when testing but so no great if you want this in production. There are lots of ways you run this: on-run-start, on-run-end, as a pre or post-hook. I am not going to do that in this example, but instead share how you can run this a stand alone operation in github actions. I’ll start with the sample code.
name: run_my_proc
on:
workflow_dispatch:
# Inputs the workflow accepts.
inputs:
name:
# Friendly description to be shown in the UI instead of 'name'
description: 'What is the reason to trigger this manually?'
# Default value if no value is explicitly provided
default: 'manual run for my stored procedure'
# Input has to be provided for the workflow to run
required: true
env:
DBT_PROFILES_DIR: ./
MSSQL_USER: ${{ secrets.MSSQL_USER }}
MSSQL_PROD: ${{ secrets.MSSQL_PROD }}
MSSQL_LOGIN: ${{ secrets.MSSQL_LOGIN }}
jobs:
run_my_proc:
name: run_my_proc
runs-on: self-hosted
steps:
- name: Check out
uses: actions/checkout@master
- name: Get dependencies # ok guess I need this anyway
run: dbt deps --target prod
- name: Run dbt run-operation
run: dbt run-operation my_macro
As you can see – we are using ‘workflow_dispatch’ as our hook for the job. You can find out more about this in the github actions documentation. So now what we have in github is the ability to run this macro on demand with a button press. Neat!
Closing thoughts
One of the challenges I have experienced with existing analytics projects on SQL Server and dbt is “what do I do about my stored procedures”. They can be very hard to fit into the dbt model in my experience. So this is my attempt at a happy medium where you can continue to use those battle tested stored procedures while continuing build out and migrate towards dbt. Github actions is a simple, nicely documented way to start moving logic away from the sql job agent, and you can run it “on-prem” if you have that requirement. Of course, you can always find me on twitter @matsonj if you have questions or comments!
A common pattern in scaling production app databases is to keep them as small as possible. Since building production apps is not my forte, I’ll lean on the commentary of experts. I like how Silvia Botros, author of High Performance MySQL, frames it below:
This architecture presents a unique challenge for analytics engineering because you now have many databases with identical schemas, and dbt sources must be enumerated in your YAML files.
I am going to share the three steps that I use to solve this problem. It should be noted that if you are comfortable with jinja, I am sure there are better, more pythonic ways to solves this problem. I have landed on this solution as something that is easy to understand, fast to develop, and fast to run (i.e. performant).
Step 1: leverage YAML anchors and aliases
Anchors and Aliases are YAML constructions that allow you to reduce repeat syntax and extend existing data nodes. You can place Anchors (&) on an entity to mark a multi-line section. You can then use an Alias (*) call that anchor later in the document to reference that section.
By using anchors and aliases, we can drastically cut down on the amount of duplicate code that we need to write in our YAML file. A simplified version of what I have is below.
- name: BASE_DATABASE
database: CUSTOMER_N
schema: DATA
tables: &SHARD_DATA
- name: table_one
identifier: name_that_makes_sense_to_eng_but_not_data
description: a concise description
- name: table_two
- name: CUSTOMER_DATABASE
database: CUSTOMER_N+1
schema: DATA
tables: *SHARD_DATA
Unfortunately with this solution, every time a new shard is added, we have to add a new line to our YAML file. While I don’t have a solution off hand, I am certain that you could generate this file with Python.
Step 2: Persist a list of your sharded databases
This next steps seems pretty obvious, but you need a list of your shards. There are multiple ways to get this data, but I will share two of them. The first is getting the list directly from your information schema.
(SQL SERVER)
SELECT * FROM sys.databases;
(SNOWFLAKE)
SELECT * FROM information_schema.databases
You can then persist that information in a dbt model that you can query later.
The second way is to create a dbt seed. Since I already have a manual intervention in step 1, I am ok with a little bit of extra work in managing a seed as well. This also gives me the benefit of source control so I can tell when additional shards came online. And of course, this gives a little finer control over what goes into your analytics area since you may have databases that you don’t want to include in the next step. An example seed is below.
Id,SourceName
1,BASE_DATABASE
2,CUSTOMER_DATABASE
Step 3: Use jinja + dbt_utils.get_column_values to procedurally generate your SQL
The of magic enabled by dbt here is that you can put a for loop inside your SQL query. This means that instead of writing out hundreds or thousands of lines of code to load your data into one place, dbt will instead generate it. Make sure that you have dbt_utils in your packages.yml file and that you have run ‘dbt deps’ to install it first.
{% set source_names = dbt_utils.get_column_values(table=ref('seed'), column='SourceName') %}
{% for sn in source_names %}
SELECT field_list,
'{{ sn }}' AS source_name
FROM {{ source( sn , 'table_one' ) }} one
INNER JOIN {{ ref( 'table_two' ) }} two ON one.id = two.id
{% if not loop.last %} UNION ALL {% endif %}
{% endfor %}
In the case of our example, since we have two records in our ‘seed’ table, this will create two SQL queries with a UNION between them. Perfect!
Now I have scaled this to 25 databases or so, so managing it by hand works fine for me. Obviously if you have thousands of databases in production in this paradigm, running a giant UNION ALL may not be feasible (also I doubt you are reading this article if you have that many databases in prod). In fact, I ran into some internal constraints with parallelization with UNION with some models, so I use pre and post-hooks to handle it in a more scalable manner for those. Again, context matters here, so depending on the shape of your data, this may not work for you. Annoyingly, this doesn’t populate the dbt docs with anything particularly meaningful so you will need to keep that in mind.
(SQL SERVER)
{{ config(
materialized = "table",
pre_hook="
DROP TABLE IF EXISTS #source;
CREATE TABLE #source
(
some_field INT
);
{% set source_names = dbt_utils.get_column_values(table=ref('seed'), column='SourceName') %}
{% for sn in source_names %}
SELECT field_list,
'{{ sn }}' AS source_name
FROM {{ source( sn , 'table_one' ) }} one
INNER JOIN {{ ref( 'table_two' ) }} two ON one.id = two.id
{% endfor %}
DROP TABLE IF EXISTS target;
SELECT * INTO target FROM #source",
post_hook="
DROP TABLE #source;
DROP TABLE target;"
)
}}
SELECT * FROM target
So there you have it, a few ways to pull multiple tables into one with dbt. Hope you found this helpful!
Alternative methods: using dbt_utils.union_relations
In theory, using dbt_utils.union_relations can also accomplish the same as step 3, but I have not tested it that way.
I’m always really curious to learn more about optimization, especially as it relates to querying data. This lead me down the journey of watching this series of lectures by the CMU database group, which really opened my mind to how to get better performance out of my data pipelines.
One of the biggest realizations for me was in a slide in the CMU lectures that indicated >90% of compute usage in OLTP databases is NOT related to transactions (things like concurrency management & memory management). The insight for me was that by stripping away those requirements, I could get much faster performance. Initially, I probed SQL Server’s In-Memory OLTP functionality (aka Hekaton), but the feedback from people in my network was either “haven’t used it” or “it was a horrible experience, don’t waste your time.”
Around the same time, I was hearing a lot of chatter related to DuckDB. Install and setup was so simple, that I figured I would download it and mess around a little bit. Since I recently had done some optimization of queries related to wordle where I was able to improve query performance 53.8x, I figured it would be good to revisit it. To say I was blown away would be an understatement.
First, the process to install DuckDB is very simple. Assuming you already have some python knowledge, it’s a single-line install with pip. Adding the dbt connector was also very simple. In fact, setting up your dbt profile is as simple as:
duckdb:
target: dev
outputs:
dev:
type: duckdb
But I digress, I actually didn’t need to even get into dbt to run this experiment. Just like my previous post, I am doing the testing with this query, which looks at two lists of words for the game “wordle” and then finds the top 500 words with the most matches (for those curious, the top matching words are: orate / roate / oater). It’s not particularly fast on postgresql, clocking around 487s (8m7s) when I run it on my laptop (postgresql running under WSL2). In the previous post, I was able to get it to run in around 17.2s by using some intermediate materializations and partitioning the compute-intensive part of the query to run in parallel (and also using a faster CPU).
With DuckDB, we are doing a little surgery on the query to pull the source data directly out of CSVs. Instead of ‘FROM table’ like in postgresql (where we first load the data to a table and then analyze it next), I am using read_csv_auto in DuckDB to pull the data straight off my harddrive.
FROM read_csv_auto('C:\Users\matso\code\wordle\data\wordle.csv',header=True)
I modified the FROM clause in both of my CTEs, and then ran the query. The results honestly astonished me.
6 seconds in DuckDB vs 487s in Postgresql.
Surely this couldn’t be right! First off – the data wasn’t even LOADED into the database since I was selecting it right off of my disk. I ran it again, 6 seconds.
An 80x increase in performance.
Honestly, I don’t think there is much left to write about here, but I have definitely been contemplating how much time I’ve spent getting pretty skilled at OLTP query optimization only to see DuckDB just do it faster. Obviously, this is not a benchmark, so performance in the real world may vary tremendously, but this is certainly enough for me to really figure out how to get this to play nicely within my analytics stack.
Footnote: I replicated the same data into SQL Server 2019 and added COLUMNSTORE indexes. Query time for the base query was approx 1m30s. So 3-4x faster than postgresql (unoptimized/tuned), but still much slower than DuckDB.
That leads me to meet stakeholders where they’re at: in Excel. And modern data warehouses like Snowflake make it really easy to do so. It’s an easy win if you’ve invested in Analytics Engineering to create clean datasets in your database. Let’s bring those datasets to your users.
Here’s how to connect Snowflake into Excel and enable live connections pivot tables in minutes. These are instructions for Windows specifically.
Step by Step Instructions
(1) Install the ODBC Driver
Click on the “Help” button in the Snowflake UI, go to “Download…” and select “ODBC Driver” and “Snowflake Repository”. Install from the file that downloads.
(2) Configure ODBC Driver
Go to your start menu and type in “ODBC” and click on ODBC Data Sources (64 bit)
Under User DSN, select Add…
Select SnowflakeDSIIDriver from the menu
Fill in the boxes as follows – though your individual situation may vary. My example uses SSO when an organization doesn’t allow direct usernames/passwords for Snowflake. Lots of options here and Snowflake has full documentation of options here.
Note: I found that lots of databases & schemas are available even after choosing some here. Not sure the full limitations, so you can play with options. I put all options in for the primary database I cared about and it worked fine.
Click on Test… to confirm it worked. Here’s the dialog if it did:
(3) Connect to database in Excel
Open Excel and go to the Data tab, click on Get Data and choose From Other Sources and pick From ODBC
From the window that pops up, pick the Snowflake connection and select OK
If successful, you’ll see a window with a dropdown showing your available databases. Use that dropdown to pick the database you want.
IMPORTANT: There is an easy way to load data directly into a Pivot Table at this point (thanks Jacob for this tip!) which will save you and teams time.
Once you select the database / schema / table you want, go to that “Load” button on the bottom and click the little down arrow next to it. Choose “Load to…”
The next menu that pops up will give you various options – pick the second one down saying PivotTable Report
DONE. You’re there. The data is now connected live to Snowflake and is available to pivot. I used Snowflake’s sample “Weather” table which I just learned has basically nothing in it, but that’s besides the point.
Parting notes
There are a couple interesting tidbits to pass both to your stakeholders as well as anyone concerned about Snowflake compute cost & data security.
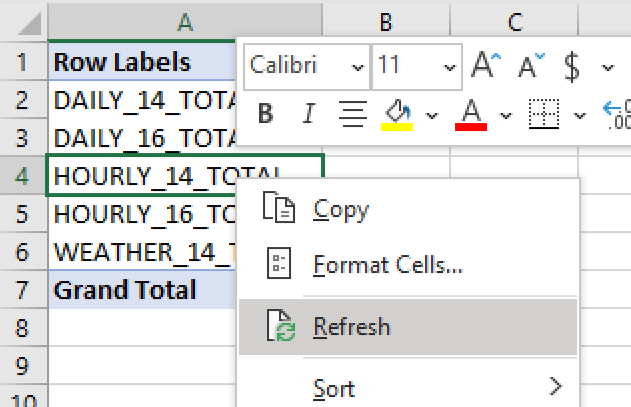
(1)Stakeholders can refresh data live from Snowflake any time. By right-clicking the pivot table and selecting “Refresh”. No more stakeholders asking you for the latest data – they can just get it anytime.
(2) Data is cached on the local machine, reducing compute costs & keeping things snappy for stakeholders. This satisfies worries from both stakeholders on performance (it’s REALLY snappy, even for huge tables) as well as those concerned on cost (compute only happens on refresh).
That’s it! Just a few installations and clicks and you’ve connected Snowflake live into Excel for any stakeholder. Happy self-serving.
Like most people, I’ve been obsessed with Wordle for the past few weeks. It’s been a fun diversion and the perfect thing to do while sipping a cup of coffee.
But of course, my brain is somewhat broken by SQL and when I saw this GitHub repo courtesy of Derek Visch, I was intrigued by the idea of using SQL to build a Wordle optimizer.
Using his existing queries, I was able to get a list of “optimal” first words. But it took forever! On my laptop, over 900 seconds. Surely this thing could be optimized.
the first dbt run of the query
For reference, you can find the query here, but I’ve pulled a point in time copy below.
{{ config( tags=["old"] ) }}
WITH guesses as (
SELECT
word,
SUBSTRING(word, 1, 1) letter_one,
SUBSTRING(word, 2, 1) letter_two,
SUBSTRING(word, 3, 1) letter_three,
SUBSTRING(word, 4, 1) letter_four,
SUBSTRING(word, 5, 1) letter_five
FROM {{ ref( 'wordle' ) }} ),
answers as (
select
word,
SUBSTRING(word, 1, 1) letter_one,
SUBSTRING(word, 2, 1) letter_two,
SUBSTRING(word, 3, 1) letter_three,
SUBSTRING(word, 4, 1) letter_four,
SUBSTRING(word, 5, 1) letter_five
from {{ ref( 'answer' ) }} ),
crossjoin as (
select
guesses.word as guess,
answers.word as answer,
CASE
WHEN answers.letter_one in (guesses.letter_one, guesses.letter_two, guesses.letter_three, guesses.letter_four, guesses.letter_five) THEN 1
ELSE 0
end as a1_match,
CASE
WHEN answers.letter_two in (guesses.letter_one, guesses.letter_two, guesses.letter_three, guesses.letter_four, guesses.letter_five) THEN 1
ELSE 0
end as a2_match,
CASE
WHEN answers.letter_three in (guesses.letter_one, guesses.letter_two, guesses.letter_three, guesses.letter_four, guesses.letter_five) THEN 1
ELSE 0
end as a3_match,
CASE
WHEN answers.letter_four in (guesses.letter_one, guesses.letter_two, guesses.letter_three, guesses.letter_four, guesses.letter_five) THEN 1
ELSE 0
end as a4_match,
CASE
WHEN answers.letter_five in (guesses.letter_one, guesses.letter_two, guesses.letter_three, guesses.letter_four, guesses.letter_five) THEN 1
ELSE 0
end as a5_match
from guesses
cross join answers),
count_answers as (
select
guess,
answer,
a1_match + a2_match + a3_match + a4_match + a5_match as total
from crossjoin),
maths_agg as (
select
guess,
sum(total),
avg(total) avg,
stddev(total),
max(total),
min(total)
from count_answers
group by guess
order by avg desc ),
final as (
select *
from maths_agg )
select *
from final
The first optimization
The first, most obvious lever to pull on was to increase compute! So I switched to my newly built gaming PC. The environment setup is win 11 pro , dbt 1.0.0, and postgres 14 (via WSL2), running on an AMD 5600G processor with 32GB of RAM, although WSL2 only has access to 8GB of RAM. I will detail the environment setup in another post.
With this increased compute, I was able to reduce run time by 3.4x, from 927s to 272s.
getting faster
The second optimization
The next level was inspecting the query itself and understand where potential bottlenecks could be. There are a couple ways to do this, one of which is using the query planner. In this case, I didn’t do that because I don’t know how to use the postgresql query planner – mostly I’ve used SQL Server so I’m a bit out of my element here.
So I took each CTE apart and made them into views & tables depending complexity. Simple queries that are light on math can be materialized as views, where as more complex, math intensive queries can be materialized as tables. I leveraged the dbt config block in the specific queries I wanted to materialize as tables.
one query, now multiple models + 1 DAG
Simply by strategically using the table materialization, we can increase performance by 9.0x – 272s to 30s.
much better
The third optimization
Visually inspecting the query further, the crossjoin model is particularly nasty as a CTE.
crossjoin as (
select
guesses.word as guess,
answers.word as answer,
CASE
WHEN answers.letter_one in (guesses.letter_one, guesses.letter_two, guesses.letter_three, guesses.letter_four, guesses.letter_five) THEN 1
ELSE 0
end as a1_match,
...
from guesses
cross join answers
First, there is a fair bit of math on each row. Secondarily, its cross joining a couple large tables and creating a 30m row model. So in round numbers, there are 5 calculations for “guess” times 5 calculations for each “answer”, for 25 calculations per row. Multiply by 25m rows, you get 750m calculations.
Now since I have a pretty robust PC with 6 cores, why not run the dbt project on 6 threads? First things first – lets change our profile to run on 6 threads.
increase thread count to 6!
With that done, I had to partition my biggest table, crossjoin, into blocks that could be processed in parallel. I did this with the following code block:
{{ config(
tags=["new","opt"],
materialized="table"
) }}
-- Since I have 6 threads, I am creating 6 partitions
SELECT 1 as partition_key, 1 as "start", MAX(id) * 0.167 as "end"
FROM {{ ref( 'guesses_with_id' ) }}
UNION ALL
SELECT 2 as partition_key, MAX(id) * 0.167+1 as "start", MAX(id) * 0.333 as "end"
FROM {{ ref( 'guesses_with_id' ) }}
UNION ALL
SELECT 3 as partition_key, MAX(id) * 0.333+1 as "start", MAX(id) * 0.5 as "end"
FROM {{ ref( 'guesses_with_id' ) }}
UNION ALL
SELECT 4 as partition_key, MAX(id) * 0.5+1 as "start", MAX(id) * 0.667 as "end"
FROM {{ ref( 'guesses_with_id' ) }}
UNION ALL
SELECT 5 as partition_key, MAX(id) * 0.667+1 as "start", MAX(id) *0.833 as "end"
FROM {{ ref( 'guesses_with_id' ) }}
UNION ALL
SELECT 6 as partition_key, MAX(id) * 0.833+1 as "start", MAX(id) as "end"
FROM {{ ref( 'guesses_with_id' ) }}
dag-tastic!
Then I split my table generation query into 6 parts. I believe this could probably be done with a macro in dbt? But I am not sure, so I did this by hand.
select
guesses.word as guess,
answers.word as answer,
...
from {{ ref( 'guesses_with_id' ) }} guesses
join {{ ref( 'guess_partition' ) }} guess_partition ON partition_key = 1
AND guesses.id BETWEEN guess_partition.start AND guess_partition.end
cross join {{ ref( 'answers' ) }} answers
Then of course, I need a view that sits on top of the 6 blocks and combines them into a single pane for analysis. The resulting query chain looks like this.
I then executed my new code. You can see in htop how all 6 threads are active on Postgres while these queries execute.
why shouldn’t I use all 6 cores?
This results in a run time of 17.2s, a 53.8x improvement from the original query on my laptop and a 15.8x improvement on the initial query on the faster pc. Interestingly, going from 1 thread to 6 threads only gave us a 50% performance increase, so there were bottlenecks elsewhere (Bus? Ram? I am not an expert in these things).
17 seconds! pretty good
Real world applications
This optimization, taken as a whole, worked for a few reasons:
It’s trivial to add more compute to a problem, although there is real hard costs incurred.
The most common SQL optimization strategy I see is "increase the Snowflake warehouse size"
The postgresql query planner was particularly inefficient in handling these CTEs – most likely calculating the same data multiple times. Materializing data as a table prevents these duplicative calculations.
Databases are great at running queries in parallel.
These exact optimization steps won’t work for every table, especially if the calculations are not discrete on a row-by-row basis. Since each calculation in core table “crossjoin” is row-based, partitioning it into pieces that can run in parallel is very effective.
Some constraints to consider when optimizing with parallelization:
Read/Write throughput maximums
Holding the relevant data in memory
Compute tx per second
This scenario is purely bottlenecked on compute – so optimizing for less compute in bulk (and then secondarily, more compute in parallel) did not hit local maximums for memory and read/write speeds. As noted above, running the threads in parallel did hit a bottleneck somewhere but I am not sure where.
If you want to try this for yourself, you can find the GitHub project here. It is built for Postgres + dbt-core 1.0.0, so can’t guarantee it works in other environments.
Hat tip to Derek for sparking my curiosity and putting his code out there so that I could use it.
PS – The best two-word combo I could come up using this code is: EARLS + TONIC.
For some, getting into data analytics outside of an academic or work environment can be very challenging – where do you start? Which database do you use? And how do you do it for low or zero cost?
In this article, I am going to walk through setting up your VM1 & database, connecting to your new remote server using Azure Data Studio, and as a bonus, connecting it to dbt. I’ve also written about setting up dbt on windows on a previous post.
First, let’s talk about requirements & recommendations:
This tutorial is focused on Windows 10 + Linux. You will need Windows 10 Pro where you install your VM.
I recommend that you set up your database on different physical machine than your dev machine. You should probably have at least 32GB of RAM.
Since we are installing the database on another machine, that machine needs to be on the same network as your development machine.
Why use a VM at all?In my experience, running a database on your dev machine makes everything extremely slow. Your database will be very greedy with resources (RAM specifically) – so keeping it in a little box that you can turn on and off allows you to keep using your machine “as normal”.
Step 1: Enable HyperV
Open powershell as administrator and run the following command:
You will need to restart your machine in order to use the HyperV features, so machine sure to do that first. The Microsoft documents to create a VM are exellent – and linked below. Make sure to select Ubuntu 20.04 when you create it.
We will do the install of SQL Server2 in the CLI on Ubuntu, which MS has laid out again very nicely in their documentation. A couple of notes when walking through this:
Make sure to select “SQL Server Express” as your edition. It limits your database size to 9GB but is otherwise relatively unencumbered by MS licensing.
Write down your SA password. You will need it later when connecting.
Step 4: Update the settings of your virtual switch
The default settings inside HyperV is for an “internal network” on your VM. This is fine if you are accessing your VM from the machine its running on, but the whole point here is that you want it to be a “remote server”. Set the virtual switch to “external network” and you can then access your VM from any machine on your network.
Step 5: Install Azure Data Studio on your dev machine – and write some SQL!
On your dev machine, make sure you can ping your VM. In my case, my VM is named “jacob-virtual-machine”, so the command to validate I can reach it is:
ping jacob-virtual-machine
If you can’t ping your VM, you have some networking issues to sort out. While I am no expert here, you will want to make sure you can see your VM outside the host (Step 4, above) and that port 1433 is open on the host and the VM.
Once that is resolved, you can download and install Azure Data Studio3. Now, with the credentials from above and you VM name, you can connect to your remote server. Everything can be left on defaults, but the avoidance of doubt, check out my connection settings below.
SQL Server Connection Settings
Now you have it all working and you have your own nice empty database to play with!
Bonus Content: Connect dbt to SQL Server
For those of you wishing to use dbt with SQL Server, check out the dbt-sqlserver github. It has great details, but I’ll summarize the key bits.
You will need to install the dbt connector:
pip install dbt-sqlserver
I also find their explanation of the profiles.yml file kind of confusing, so I’ve included my own below for reference:
1 You can also probably do this with WSL2, and not install a Linux VM. However, I am going to be running more software on the VM later and I want to split it to another machine. You can also use docker over top of all of this, which I may cover in another post. 2 I’m choosing SQL Server for a couple reasons: I am familiar with it and the documentation and community are large. PostgreSQL also works here, which has the advantage of having a default dbt connector. 3 SSMS works here too, but Azure Data Studio has the advantage of being cross platform. If you are using dbt, you need a SQL runner anyway as the VS code options aren’t great.
I gave a talk last week about “Data to Dashboard” and I wanted to share it here, too. There is a lot of discussion in the analytics space about dashboards and how to make them look good but less about how to get to that point. This is my take on the subject – I hope you enjoy it.